在当今动态变化的数字环境中,推荐系统面临着两大核心挑战:一是用户兴趣随时间不断变化的概念漂移现象,二是面对新用户或新内容时缺乏历史交互数据的冷启动困境。传统批量训练模式由于更新周期长、响应迟缓,难以有效应对这些实时性挑战。而实时训练机制,通过持续、流式地处理用户行为数据,能够在极短时间内将最新的交互信号融入模型,从而动态捕捉用户兴趣的演变趋势,显著提升模型的新鲜度与推荐准确性。
概念漂移
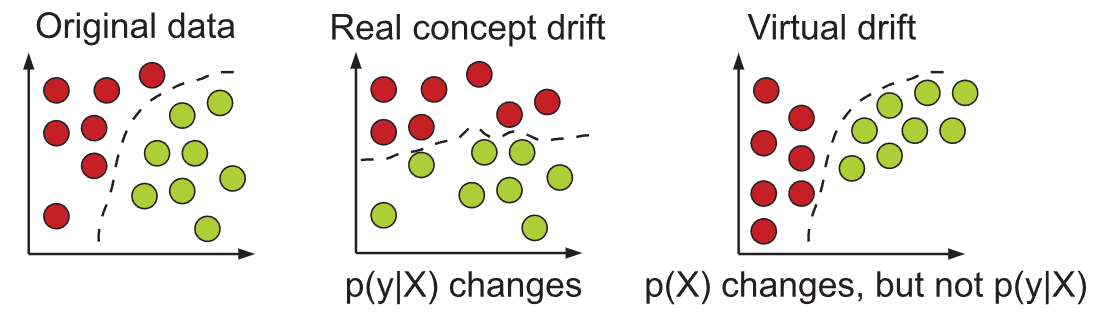
概念漂移 (Concept drift) [1] 指的是输入数据和目标变量之间的关系随时间动态变化。根据贝叶斯决策理论,分类任务可以通过类别的先验概率 p(y) 和给定类别的条件概率密度函数 p(X|y) 来描述,其中 X 是输入特征, y 是目标变量。分类决策通常依据后验概率 p(y|X) ,其表达式为: p(y|X) = \frac{p(y) p(X|y)}{p(X)}
其中 p(X) = \sum_{y=1}^{c} p(y) p(X|y) , c 是类别数量。
概念漂移在时间点 t_0 和 t_1 之间发生时,其数学定义为:
\exists X : p_{t_0}(X, y) \ne p_{t_1}(X, y)这意味着在某个输入 X 下,联合概率分布 p(X, y) 发生了变化。这种变化可能源于以下几个方面:
- 先验概率变化: p(y) 改变。
- 类条件概率变化: p(X|y) 改变。
- 后验概率变化:作为结果, p(y|X) 改变,从而影响预测决策。
- 输入数据分布变化: p(X) 改变。
从预测的角度来看,只有那些影响预测决策的变化才需要适应。
这篇 Survey 主要区分了两种类型的概念漂移:
-
Real Concept Drift (真实概念漂移):
- 指 p(y|X) 的变化。这意味着给定相同的输入 X ,输出 y 的条件概率发生了变化。模型的决策边界因此需要调整。
- 这种变化可能伴随 p(X) 的变化,也可能不伴随。
- 示例:用户对新闻文章的兴趣改变,原本相关的新闻类型变得不相关,即使新闻内容的分布 p(X) 没有变。
-
Virtual Drift (虚拟漂移):
- 指 p(X) 的变化,但 p(y|X) 保持不变。这意味着输入数据的分布发生了变化,但输入和输出之间的基本关系(即决策边界)没有改变。
- 虽然不直接影响 p(y|X) ,但如果模型依赖 p(X) (例如,某些基于密度估计的算法),虚拟漂移也可能影响模型的性能,因为它改变了模型“看到”的输入空间区域。
- 示例:新闻门户的编辑改变了写作风格,导致新闻文章的特征分布 p(X) 变化,但用户对“居住房屋”的兴趣(即 p(y|X) )保持不变。
在实际应用中,真实概念漂移、虚拟漂移、先验概率漂移以及新概念(novelty)的出现,往往会以各种组合形式同时发生。
概念漂移的解决之所以充满挑战,主要体现在以下几个方面:
-
突发性和不可预测性:大多数情况下,数据生成过程的变化是意外且不可预测的。模型需要实时检测并适应,而不能依赖预设的知识。
-
变化模式多样性:漂移可能表现为突然的 (sudden/abrupt) 变化,也可能为渐进的 (incremental/gradual) 变化,甚至会出现周期性 (reoccurring) 变化。区分真实漂移与离群值 (outlier) 或噪声也很关键,因为噪声不需要适应。

-
资源限制:在数据流 (data streams) 环境中,算法必须在有限的内存和有限的处理时间内运行。这意味着无法存储所有历史数据或进行昂贵的离线重训练。
-
反馈延迟:在许多实际应用中,真实的标签 y_t (即反馈)可能延迟到达,甚至根本不可用。这使得模型很难及时评估其当前性能并判断是否发生了漂移,特别是真实概念漂移。
-
稳定性-可塑性困境 (Stability-Plasticity Dilemma):模型需要足够“稳定”以抵御噪声和暂时性波动,但同时又需要足够“可塑”以快速适应新概念。在两者之间找到平衡是一个固有的难题。

[1] 中作者提供的思路:在反馈延迟下区分与适应。
- 实时监测 p(X) 变化(无监督,早期信号):比较两个时间窗口 W_{old} 和 W_{new} 的经验分布是否有 D(P_{W_{new}}(X) || P_{W_{old}}(X)) > \tau_X ,这里 D 可以是 KL 散度,Wasserstein 距离等;还可以进行对特征均值、方差进行 Page-Hinkley (PH) 或 CUSUM 测试。例如,对特征 j 的均值 \mu_j : g_t = \max(0, g_{t-1} + (X_{t,j} - \mu_{t,j} - \delta)) 。
- 滞后监测 p(y|X) 变化(依赖延迟反馈):使用延迟到达的真实标签 y_t 计算预测误差 e_t = f(\hat{y}_t, y_t) 。例如,使用 ADWIN 监测误差均值 \mu_e ,也就是是否存在两个时间窗口 W_0,W_1 ,有: |\hat{\mu}_{W_0} - \hat{\mu}_{W_1}| > \epsilon ;同样可以使用 CUSUM/PH 来应用到误差流。
冷启动
冷启动 (Cold Start) [2] 问题指的是由于缺乏足够的用户-物品交互历史数据,导致推荐系统难以对新用户或新物品生成有效、个性化推荐的情况。也就是说当给定用户 u 或物品 v 没有任何偏好信息可用时,即 V(u) = \emptyset (用户 u 没有表达过任何偏好) 和 / 或 U(v) = \emptyset (物品 v 没有被任何用户表达过偏好)。这意味着传统的协同过滤方法在这些情况下无法直接应用,因为它们严重依赖于用户-物品交互数据来学习潜在表示或计算相似性。
具体来说,难点如下:
- 数据稀疏性:冷启动的本质是数据稀疏性在极端情况下的体现。对于新用户/物品,其对应的偏好矩阵行或列是全零的,无法进行有效的模型训练或相似性计算。
- 传统协同过滤方法的失效:基于邻域的 CF 方法 (Neighbor-based CF) 无法找到新用户/物品的邻居,因为它们没有共同的交互记录;基于模型的 CF 方法 (Model-based CF),特别是潜在模型 (Latent Models) 如矩阵分解,在没有交互数据的情况下,无法学习到新用户或新物品的准确潜在表示。如本文所述,潜在模型在偏好信息充足时表现良好,但在高度稀疏的冷启动设置下性能会下降。
- 模型复杂度与优化:现有的混合模型通常会引入额外的目标项,使模型学习和推理变得复杂。例如,本文提到 CDL [22] 包含四个目标项,并需要调整三个组合权重,这在大规模数据集上进行调优既昂贵又耗时。
- 目标不匹配:一些混合模型的内容部分目标函数是生成式的,迫使模型去“解释”内容,而不是直接用于最大化推荐准确性。这可能导致模型容量的浪费,去建模对推荐不那么有用的内容方面。
DropoutNet 的思想:对输入层的偏好潜在表示随机应用 Dropout,显式地模拟冷启动场景。
这种方法强制模型在偏好数据缺失时,转而学习如何有效利用内容信息来重建原始的推荐得分,从而在不引入复杂多目标函数的情况下,使模型同时具备优秀的温启动表现和最先进的冷启动泛化能力,且能灵活应用于任何现有潜在模型。
接收两类输入特征来描述用户 u 和物品 v :
- 偏好潜在表示 (Preference Latent Representation):来自现有协同过滤(CF)潜在模型(如 WMF)学习到的低维稠密向量:用户 u 的偏好表示: U_u \in \mathbb{R}^D 、物品 v 的偏好表示: V_v \in \mathbb{R}^D ,其中 D 是潜在空间的维度。
- 内容特征 (Content Features):来自用户或物品的额外内容信息(如文本、图像等),经过处理后的固定长度特征向量:用户 u 的内容特征: \Phi_{U_u} 、物品 v 的内容特征: \Phi_{V_v}
因此,模型的输入是联合的偏好-内容向量: [U_u, \Phi_{U_u}] 用于用户模型, [V_v, \Phi_{V_v}] 用于物品模型。
包含两个独立的深度神经网络:
- 用户 DNN: f_U(\cdot, \cdot) ,将用户输入映射到新的潜在空间,生成用户 u 的新潜在表示 \hat{U}_u = f_U(U_u, \Phi_{U_u})
- 物品 DNN: f_V(\cdot, \cdot) ,将物品输入映射到新的潜在空间,生成物品 v 的新潜在表示 \hat{V}_v = f_V(V_v, \Phi_{V_v})
- 最终的推荐相关性得分 \hat{s}_{uv} 通过这两个新的潜在表示的点积来估计: \hat{s}_{uv} = \hat{U}_u \hat{V}_v^T 。
DropoutNet 的训练目标是最小化其预测得分与原始输入潜在模型生成得分之间的差异。原始潜在模型的得分通常由 U_u V_v^T 给出。因此,损失函数为:
O = \sum_{u,v} (U_u V_v^T - f_U(U_u, \Phi_{U_u}) f_V(V_v, \Phi_{V_v})^T)^2 = \sum_{u,v} (U_u V_v^T - \hat{U}_u \hat{V}_v^T)^2这个目标函数在所有输入(偏好和内容)都可用时,促使 f_U 和 f_V 网络学习一个映射,使得它们的输出 \hat{U}_u, \hat{V}_v 能够尽可能地重现输入潜在模型 U_u, V_v 的预测能力。当 Dropout Rate 为 0 时,模型会倾向于学习一个接近恒等函数,即 \hat{U}_u \approx U_u 和 \hat{V}_v \approx V_v ,从而保留原始潜在模型在温启动场景下的准确性。
-
João Gama, Indrė Žliobaitė, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A survey on concept drift adaptation. ACM Comput. Surv. 46, 4, Article 44 (April 2014), 37 pages. https://doi.org/10.1145/2523813
综述了在线监督学习场景中,输入数据与目标变量之间关系随时间变化的“概念漂移”(Concept Drift)及其适应机制。
-
Volkovs, Maksims, Guangwei Yu and Tomi Poutanen. “DropoutNet: Addressing Cold Start in Recommender Systems.” Neural Information Processing Systems (2017).
对推荐系统中的“冷启动”问题,本文提出了一个名为 DropoutNet 的深度神经网络模型,它旨在通过训练过程中对输入进行Dropout操作,以此显式地使模型适应缺失的偏好信息,来解决用户或物品缺乏偏好信息的情况。